Scheduler Internals
Architecture
Timeslice
The scheduler defines a fixed time interval during which each thread in the system must run at least once. The interval is divided among threads proportionally to their weights. The resulting interval (after division) is what we call the timeslice.
Priority
A thread’s weight is essentially its priority, or niceness in UNIX parlance. Threads with lower niceness have higher weights and vice versa.
vruntime
When a thread runs, it accumulates vruntime (runtime of the thread divided by its weight). Once a thread’s vruntime exceeds its assigned timeslice, the thread is pre-empted from the CPU if there are other runnable threads available. *A thread might also get pre-empted if another thread with a smaller vruntime is awoken.
runquque
Threads are organized in a runqueue, implemented as a red-black tree, in which the threads are sorted in the increasing order of their vruntime. When a CPU looks for a new thread to run it picks the leftmost node in the red-black tree, which contains the thread with the smallest vruntime.
per-core runqueues
On multi-core systems, CFS becomes quite complex.In multicore environments the implementation of the scheduler becomes substantially more complex. Scalability con- cerns dictate using per-core runqueues.
load balancing
However, in order for the scheduling algorithm to still work correctly and efficiently in the presence of per-core runqueues, the runqueues must be kept balanced. Therefore, what Linux and most other schedulers do is periodically run a load-balancing algorithm that will keep the queues roughly balanced.
“emergency” load balancing
Conceptually, load balancing is simple. In 2001, CPUs were mostly single-core and commodity server systems typ- ically had only a handful of processors. It was, therefore, difficult to foresee that on modern multicore systems load balancing would become challenging. Load balancing is an expensive procedure on today’s systems, both computation- wise, because it requires iterating over dozens of runqueues, and communication-wise, because it involves modifying re- motely cached data structures, causing extremely expensive cache misses and synchronization. As a result, the scheduler goes to great lengths to avoid executing the load-balancing procedure often. At the same time, not executing it often enough may leave runqueues unbalanced. When that hap- pens, cores might become idle when there is work to do, which hurts performance. So in addition to periodic load- balancing, the scheduler also invokes “emergency” load bal- ancing when a core becomes idle, and implements some load-balancing logic upon placement of newly created or newly awoken threads. These mechanisms should, in theory, ensure that the cores are kept busy if there is work to do.
Scheduler Classes
The Linux scheduler is modular, enabling different algorithms to schedule different types of processes.This modularity is called scheduler classes. Scheduler classes enable different, pluggable algorithms to coexist, scheduling their own types of processes. Each scheduler class has a priority.The base scheduler code, which is defined in kernel/sched.c , iterates over each scheduler class in order of priority. The highest priority scheduler class that has a runnable process wins, selecting who runs next.

CFS
The Completely Fair Scheduler (CFS) is the registered scheduler class for normal processes, called SCHED_NORMAL in Linux (and SCHED_OTHER in POSIX). CFS is defined in kernel/sched_fair.c.
Real-time Scheduling
Linux provides two real-time scheduling policies, SCHED_FIFO and SCHED_RR. Via the scheduling classes framework, these real-time policies are managed by a special real-time scheduler, defined in kernel/sched_rt.c
SCHED_FIFO
SCHED_FIFO implements a simple first-in, first-out scheduling algorithm without timeslices. A runnable SCHED_FIFO task is always scheduled over any SCHED_NORMAL tasks. When a SCHED_FIFO task becomes runnable, it continues to run until it blocks or explic- itly yields the processor; it has no timeslice and can run indefinitely. Only a higher priority SCHED_FIFO or SCHED_RR task can preempt a SCHED_FIFO task.Two or more SCHED_FIFO tasks at the same priority run round-robin, but again only yielding the processor when they explicitly choose to do so. If a SCHED_FIFO task is runnable, all tasks at a lower priority cannot run until it becomes unrunnable.
SCHED_RR
SCHED_RR is identical to SCHED_FIFO except that each process can run only until it exhausts a predetermined timeslice. That is, SCHED_RR is SCHED_FIFO with timeslices—it is a real-time, round-robin scheduling algorithm.When a SCHED_RR task exhausts its timeslice, any other real-time processes at its priority are scheduled round-robin.The timeslice is used to allow only rescheduling of same-priority processes.As with SCHED_FIFO , a higher-priority process always immediately preempts a lower-priority one, and a lower-priority process can never preempt a SCHED_RR task, even if its timeslice is exhausted.
Real-time Scheduler Notes
Both real-time scheduling policies implement static priorities.The kernel does not calculate dynamic priority values for real-time tasks.This ensures that a real-time process at a given priority always preempts a process at a lower priority.
Soft real-time
The real-time scheduling policies in Linux provide soft real-time behavior. Soft real-time refers to the notion that the kernel tries to schedule applications within timing deadlines, but the kernel does not promise to always achieve these goals. Conversely, hard real-time systems are guaranteed to meet any scheduling requirements within certain limits. Linux makes no guarantees on the capability to schedule real-time tasks.
Scheduler Priority
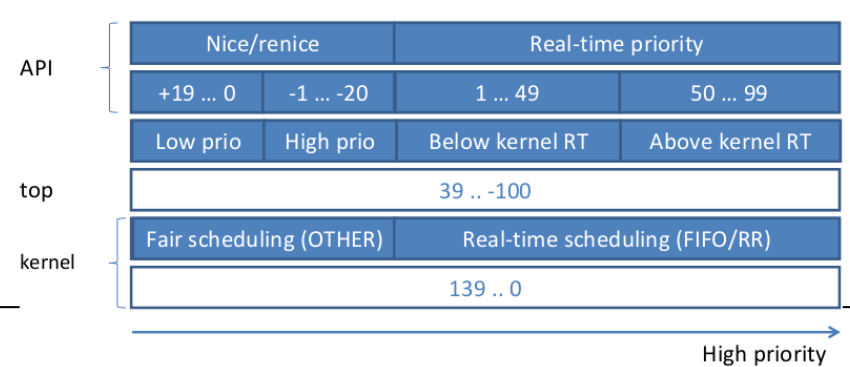
Implementation
The Scheduler Entry Point
The main entry point into the process schedule is the function schedule() , defined in kernel/sched/core.c .This is the function that the rest of the kernel uses to invoke the process scheduler, deciding which process to run and then running it. schedule() is generic with respect to scheduler classes.That is, it finds the highest priority scheduler class with a runnable process and asks it what to run next.
next = pick_next_task(rq, prev);
rq = context_switch(rq, prev, next);
balance_callback(rq);
The pick_next_task() function goes through each scheduler class, starting with the highest priority, and selects the highest priority process in the highest priority class:
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
#define sched_class_highest (&stop_sched_class)
#define for_each_class(class) \
for (class = sched_class_highest; class; class = class->next)
const struct sched_class *class = &fair_sched_class;
for_each_class(class) {
p = class->pick_next_task(rq, prev);
if (p) return p;
}
Sleeping and Waking Up
Tasks that are sleeping (blocked) are in a special nonrunnable state. A task sleeps for a number of reasons, but always while it is waiting for some event. The event can be a specified amount of time, more data from a file I/O, or another hardware event. A task can also involuntarily go to sleep when it tries to obtain a contended semaphore in the kernel.
Whatever the case, the kernel behavior is the same: The task marks itself as sleeping, puts itself on a wait queue, removes itself from the red-black tree of runnable, and calls schedule() to select a new process to execute. Waking back up is the inverse:The task is set as runnable, removed from the wait queue, and added back to the red-black tree.
As discussed in the previous chapter, two states are associated with sleeping, TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE .They differ only in that tasks in the TASK_UNINTERRUPTIBLE state ignore signals, whereas tasks in the TASK_INTERRUPTIBLE state wake up prematurely and respond to a signal if one is issued. Both types of sleeping tasks sit on a wait queue, waiting for an event to occur, and are not runnable.
Wait Queues
Sleeping is handled via wait queues.A wait queue is a simple list of processes waiting for an event to occur. Wait queues are represented in the kernel by wake_queue_head_t. Wait queues are created statically via DECLARE_WAITQUEUE() or dynamically via init_waitqueue_head(). Processes put themselves on a wait queue and mark themselves not runnable. When the event associated with the wait queue occurs, the processes on the queue are awakened. It is important to implement sleeping and waking correctly, to avoid race conditions.
Some simple interfaces for sleeping used to be in wide use.These interfaces, however, have races: It is possible to go to sleep after the condition becomes true. In that case, the task might sleep indefinitely.Therefore, the recommended method for sleeping in the kernel is a bit more complicated:
/* ‘q’ is the wait queue we wish to sleep on */
DEFINE_WAIT(wait);
add_wait_queue(q, &wait);
while (!condition) {
/* condition is the event that we are waiting for */
prepare_to_wait(&q, &wait, TASK_INTERRUPTIBLE);
if (signal_pending(current))
/* handle signal */
schedule();
}
finish_wait(&q, &wait);
The task performs the following steps to add itself to a wait queue:
- Creates a wait queue entry via the macro DEFINE_WAIT() .
- Adds itself to a wait queue via add_wait_queue() .This wait queue awakens the process when the condition for which it is waiting occurs. Of course, there needs to be code elsewhere that calls wake_up() on the queue when the event actually does occur.
- Calls prepare_to_wait() to change the process state to either TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE .This function also adds the task back to the wait queue if necessary, which is needed on subsequent iterations of the loop.
- If the state is set to TASK_INTERRUPTIBLE , a signal wakes the process up.This is called a spurious wake up (a wake-up not caused by the occurrence of the event). So check and handle signals.
- When the task awakens, it again checks whether the condition is true. If it is, it exits the loop. Otherwise, it again calls schedule() and repeats.
- Now that the condition is true, the task sets itself to TASK_RUNNING and removes itself from the wait queue via finish_wait() .
If the condition occurs before the task goes to sleep, the loop terminates, and the task does not erroneously go to sleep. Note that kernel code often has to perform various other tasks in the body of the loop. For example, it might need to release locks before calling schedule() and reacquire them after or react to other events.
Waking Up
Waking is handled via wake_up() , which wakes up all the tasks waiting on the given wait queue. It calls try_to_wake_up() , which sets the task’s state to TASK_RUNNING , calls enqueue_task() to add the task to the red-black tree, and sets need_resched if the awakened task’s priority is higher than the priority of the current task.The code that causes the event to occur typically calls wake_up() itself. For example, when data arrives from the hard disk, the VFS calls wake_up() on the wait queue that holds the processes waiting for the data.
An important note about sleeping is that there are spurious wake-ups. Just because a task is awakened does not mean that the event for which the task is waiting has occurred; sleeping should always be handled in a loop that ensures that the condition for which the task is waiting has indeed occurred.
Time Accounting
All process schedulers must account for the time that a process runs. Most Unix systems do so, as discussed earlier, by assigning each process a timeslice. On each tick of the system clock, the timeslice is decremented by the tick period. When the timeslice reaches zero, the process is preempted in favor of another runnable process with a nonzero timeslice.
Complexity
complexity of O(log N), where N is the number of tasks in the runqueue. Choosing a task can be done in constant time O(1), but reinserting a task after it has run requires O(log N) operations, because the runqueue is implemented as a red-black tree.