Storage Stack
Overview
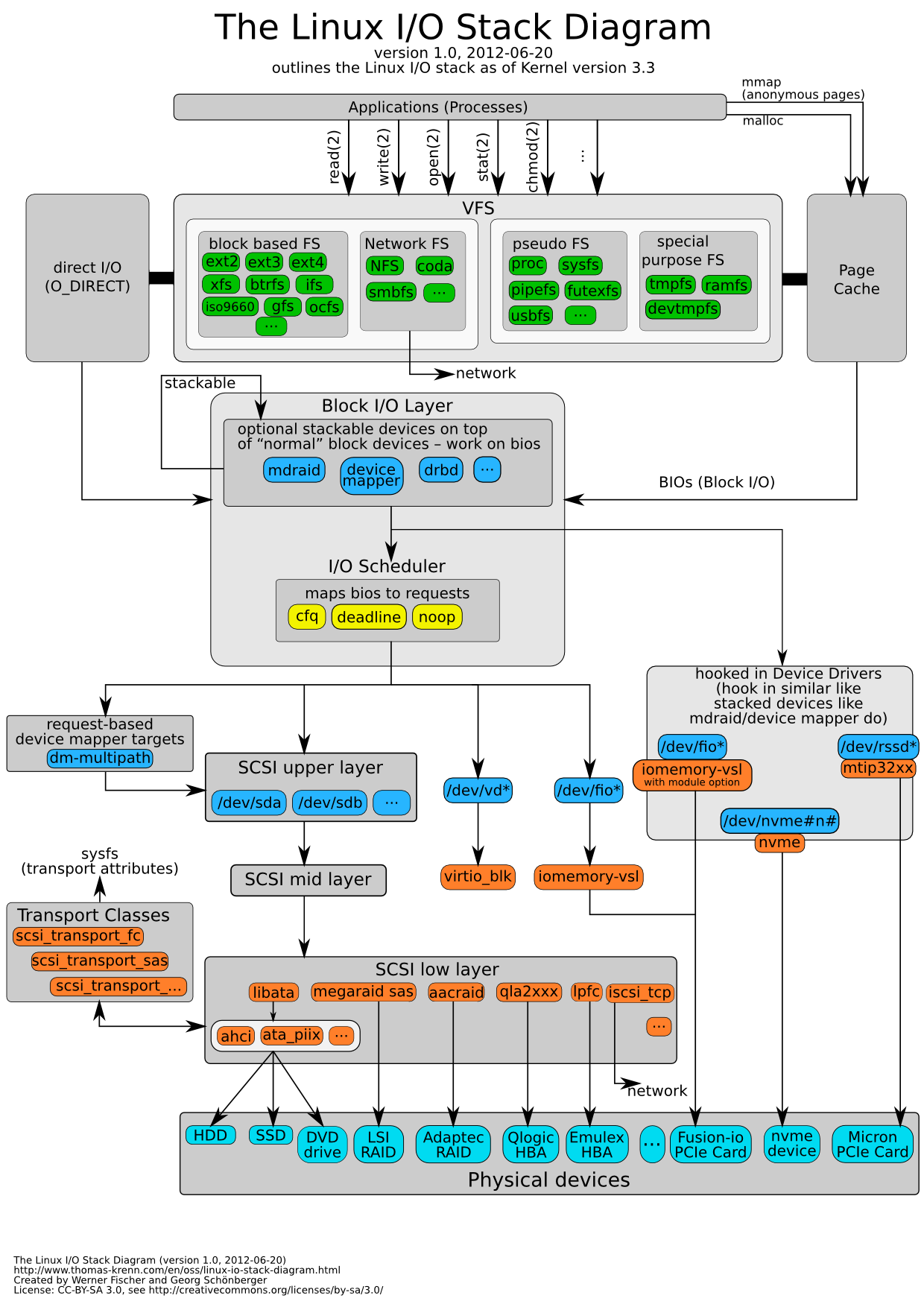
Linux 3.3 I/O Stack
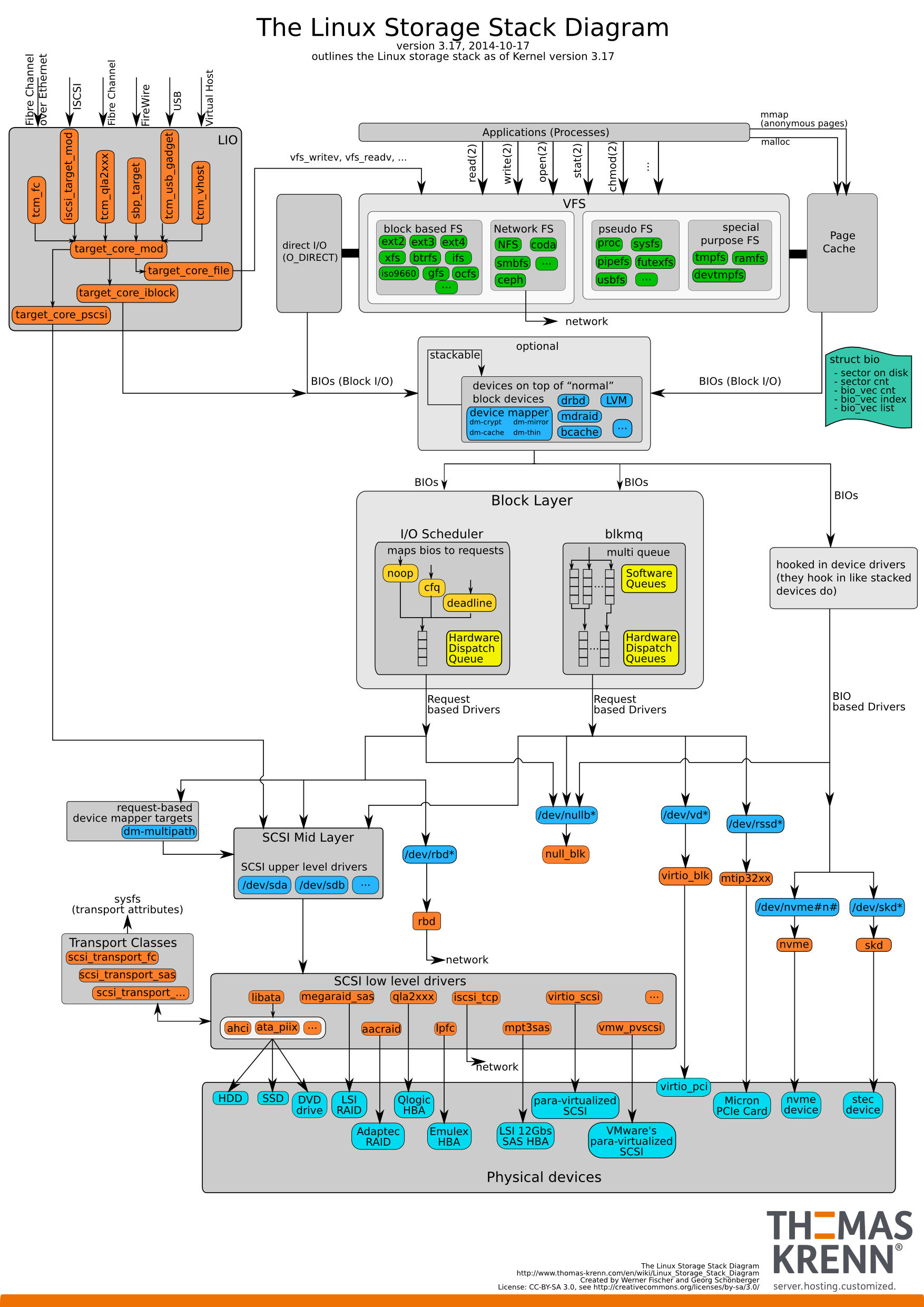
Linux 3.17 I/O Stack
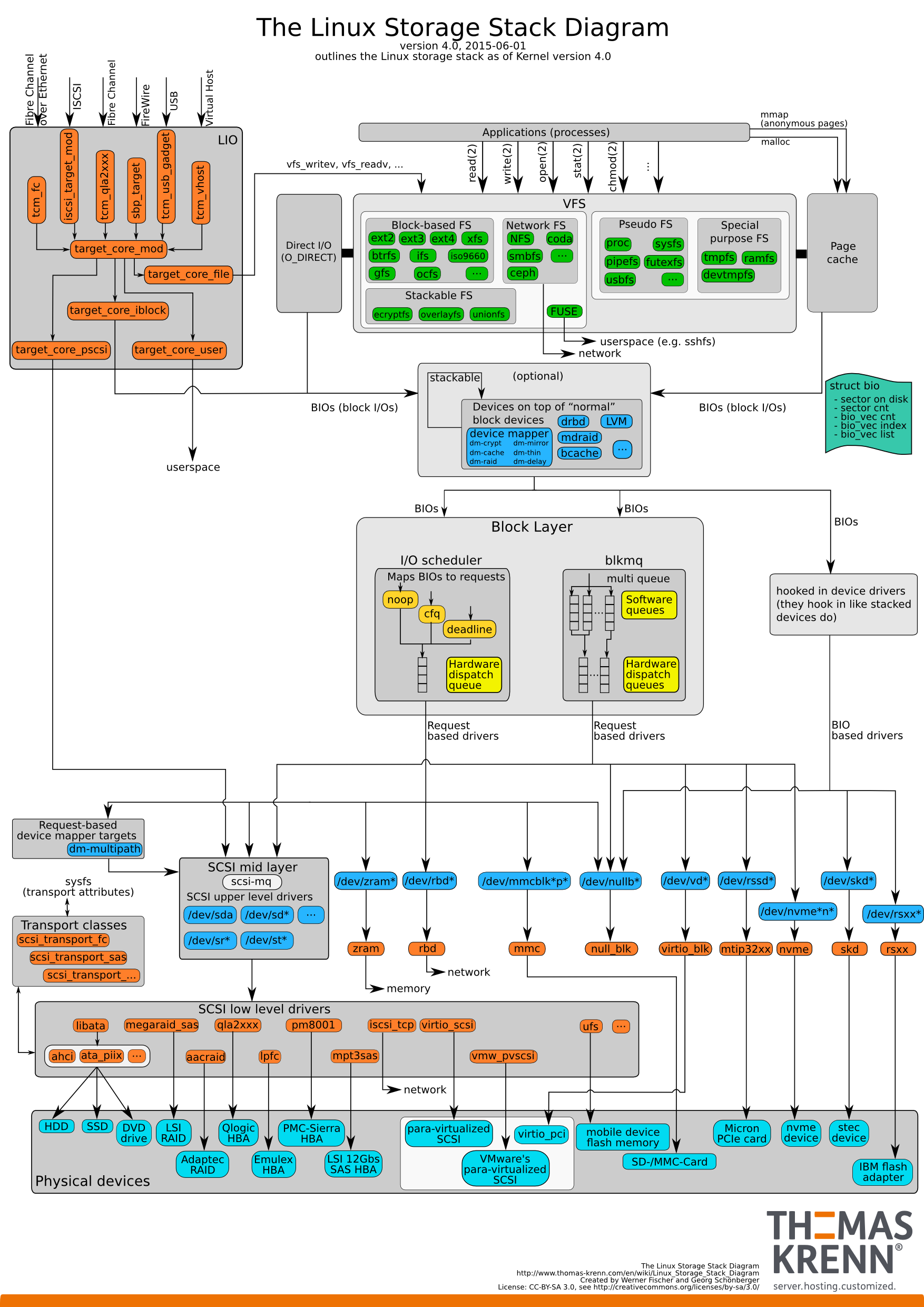
Linux 4.0 I/O Stack
User's View
To start working with files, user needs to build file system layout on top of storage devices (mkfs) and then to mount newly created file system somewhere in the hierarchy of the root file system (mount). For example /dev/sda is the special block device that represents first SCSI disk in the system.
mkfs.ext4 /dev/sda
mkdir /mnt/disk2
mount /dev/sda1 /mnt/disk2
After creating file system each application can access, modify and create files and directories. These actions can be performed using set of system calls which are exposed by the Linux kernel.
open
close
read
write
unlink
mkdir
rmdir
readdir
VFS
To support different types of file systems Linux introduced common layer called the Virtual File System layer (VFS) [7]. This layer consists of set of objects and callbacks which must be implemented by any new file system. The VFS layer hooks into Linux I/O stack and redirects any I/O operation coming from user space into specific implementation of the current file system. The implementation of the I/O operation manipulates VFS objects and interacts with the block device to read and write persistent data. The most important objects of the VFS layer are the superblock, the inode, the dentry, the file, and the address space.
The Superblock
A superblock object, represented by the super_block structure, is used to represent file system. It includes meta data about the file system such as it’s name, size and state. Additionally it contains reference to the block device on which the file system is stored and to the lists of other file system objects (inodes, files, and so on). Most of the file system store the superblock on the block device with redundancy to overcome corruptions. Whenever we mount file system the first step is to retrieve the superblock and build it’s representation in memory.
The Index Node (Inode)
The index node or inode represents an object in file system. Each object has a unique id. This object can be regular file, directory, or special objects like symbolic links, devices, FIFO queues, or sockets. The inode of a file contains pointers to data blocks with file contents. Directory inodes contain pointers to blocks that store the name-to-inode associations. Operations on an inode allow to modify it’s attributes and to read/write its data.
Directory Entries (Dentry)
The VFS implements I/O system calls that take a path name as argument. This path name needs to be translated into specific inode by traversing path components and reading next component inode info from block device. To reduce the overhead of translating path component to inode, the kernel generates dentry objects that contain pointer to the proper inode object. These dentries stored in global file system cache and can be retrieved very quickly without additional overhead of reading from block device.
The Representation of Open Files
A file object represents file opened by user space process. It connects the file to the underlying inode and has reference to implementation of file operations, such as read, write, seek and close. The user space process holds an integer descriptor which is mapped by the kernel to the actual file structure whenever file system call performed.
Page Cache
The VFS layer operates on its objects to implement file system operation and eventually decides to read/write data to disk. Unfortunately disk access is relatively slow. This is why Linux kernel uses page cache mechanism to speed up storage access. All I/O in the system performed using page-size blocks. On read request, we search for the page in the cache and bring it from the underlying block device if it is not already in the cache. On write request we update the page in the cache with new data. The modified block may be sent immediately to the block device (“sync-ed”), or it may remain in the modified (dirty) state in the cache, depending on the synchronization policy of the kernel for the particular file system and file. Another advantage of the page cache is the ability to share same pages between different processes without the need to duplicate data and make redundant requests to block device.
The page cache is manipulated using address_space structure. This structure contains radix tree of all pages in specific address space and many address spaces can be used to isolate pages with similar attributes. Inode object contains link to address_space and to set of operations on address space which allow manipulation of pages.
Practically all I/O operations in Linux rely on page cache infrastructure. The only exception to this rule is when user opens file with O_DIRECT flag enabled. In this case the page cache is bypassed and the I/O operations pass directly to the underlying block device.
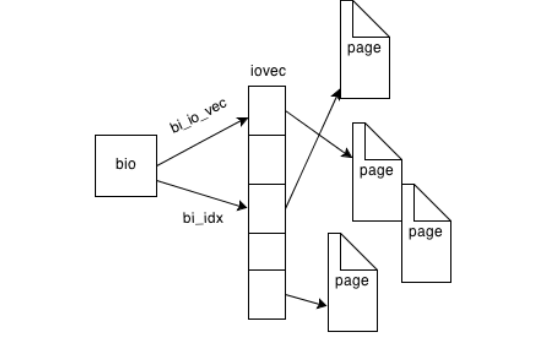
Block I/O Requests
Eventually the page cache layer needs to write/read pages from the block device. For this purpose special structure called bio created. The structure encapsulates an array of entries
that point to individual memory pages that the block device needs to read/write.
Requests and Request Queues
Bio structures are embedded into request structures that are placed on the request queue of the block device. The kernel rearranges and merges requests to achieve better I/O performance. For example, requests for adjacent blocks may be merged, or requests may be sorted by an elevator algorithm to minimize disk-arm movement, etc. These rearrangements are performed by an I/O scheduler; the Linux kernel provides several such schedulers.
The Block Device and the SCSI Layer
Requests placed on a queue are handled by a block device driver. In modern versions of Linux, the block device driver responsible for almost all persistent storage controllers is the SCSI driver. The SCSI layer in Linux is a large subsystem that is responsible to communicate with storage devices that use the SCSI protocol (which means almost all storage devices). Using this layer I/O request is submitted to the physical device in a form of SCSI command. When a device completes handling a request, its controller will issue an interrupt request. The interrupt handler invokes a completion callback to release resource and return data to the higher layers (the file system and eventually the application).
SCSI
SCSI (Small Computer Systems Interface) has emerged as a dominant protocol in the storage world. It is constructed from numerous standards, interfaces and protocols which specify how to communicate with a wide range of devices. SCSI is most commonly used for hard disks, disk arrays, and tape drives. Many other types of devices are also supported by this rich standard. The Linux kernel implements a complex SCSI subsystem and utilizes it to control most of the available storage devices.
History
SCSI is one of the oldest protocols that still evolve today. SCSI came to the world around 1979 when computer peripheral manufacturer Shugart Associates introduced the "Shugart Associates System Interface" (SASI). This proprietary protocol and interface later evolved into the SCSI protocol, with SCSI-1 standard released in 1986 and SCSI-2 in 1994. Early versions of SCSI defined both the command set and the physical layer (so called SCSI cables and connectors). The evolution of SCSI protocol continued with the SCSI-3 standard [11], which introduced new modern transport layers, including Fibre Channel (FC), Serial attached SCSI (SAS) and SCSI over IP (iSCSI).
Today SCSI is popular on high-performance workstations and servers. High-end arrays (RAID systems) almost always use SCSI disks although some vendors now offer SATA based RAID systems as a cheaper option.
Architecture
The SCSI protocol implements client-server architecture . The client called “initiator”
sends commands to the server which is called “target”. The target processes the command and returns response to the initiator. Usually we see Host Base Adapter (HBA) device in the role of initiator and we have several storage devices (disk, tape, CD-ROM) which perform as targets.
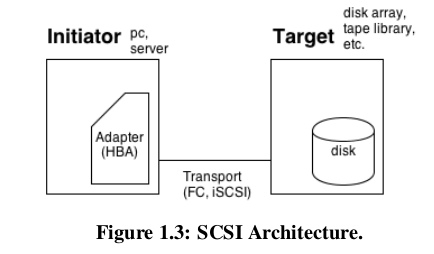
Each target device can also be subdivided into several Logical Units (LUNs). The initiator starts by sending REPORT_LUNS command which returns map of the available LUNS that the target exposes. Later the initiator can send commands directed to specific LUN. In this way single device can expose several functional units. For example a tape library which is used for data backup can expose a robotic arm on the first LUN and the tape devices which used to read/write cartridges on the rest of the LUNs.
Commands
A SCSI command and its parameters are sent as a block of several bytes called the Command De-
scriptor Block (CDB). Each CDB can be a total of 6, 10, 12, or 16 bytes. Later versions of the SCSI standard also allow for variable-length CDBs but this format is not frequently used in storage systems.
The first byte of the CDB is the Operation Code. It is followed by the LUN in the upper three bits of the second byte, by the Logical Block Address (LBA) and transfer length fields (Read and Write commands) or other parameters.

At the end of command processing, the target returns a status code byte (0x0 - SUCCESS, 0x2 -CHECK CONDITION, 0x8 - BUSY and etc’). When the target returns a Check Condition status code, the initiator will usually issue a SCSI Request Sense command in order to obtain a key code qualifier (KCQ) which specify the reason for failure.
SCSI commands can be categorized into groups using data transfer direction criteria: non-data commands (N), writing data to target commands (W), reading data from target commands (R) and bidi-rectional read/write commands (B).
Other option is to separate SCSI commands based on the device they apply to: block commands (disk drive), stream commands (tape drive), media changer commands (jukebox), multi-media commands(CD-ROM), controller commands (RAID) and object based storage commands (OSD).
Examples of popular commands include: REPORT LUNS that returns LUNs exposed by the device, TEST UNIT READY that queries device to see if it is ready for data transfers, INQUIRY that returns basic device information and REQUEST SENSE that returns any error codes from the previous command that returned an error status.
Linux SCSI Drivers
The SCSI subsystem in Linux kernel is using a layered architecture with three distinct
layers. The upper layer represents kernel interface to several categories of devices (disk, tape, cdrom and generic). The mid layer is used to encapsulate SCSI error handling and to transform kernel request which come from upper layer into matching SCSI commands. And finally, the lowest layer controls a variety of physical devices and implements their unique physical interfaces to allow communication with them.
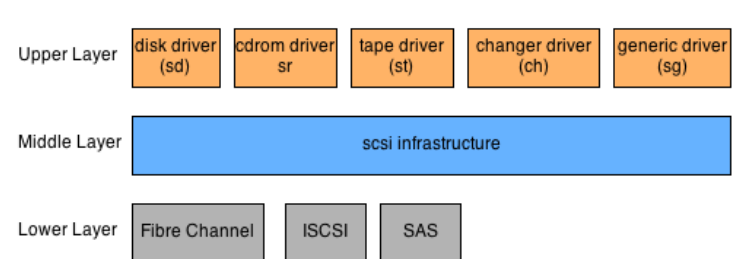
The SCSI Upper Layer
The purpose of the SCSI upper layer is to expose high level interfaces that introduce different families of scsi devices into user space. With these interfaces (special device files), user space application can mount file system on top of block devices or control SCSI device by using specific ioctl commands. There are 5 main modules implemented in this layer. These modules allow to control, disk, cdrom/dvd, tape, media changer and generic SCSI devices.
Disk Block Device
The SCSI disk driver is implemented in drivers/scsi/sd.c. It registers itself as kernel driver which will handle any SCSI disk that kernel detects. Then when existing or new SCSI disk is detected by the kernel, the driver will create block device (usually called sda, sdb and so on). This device can be used to read/write to the disk by invoking sd_prep_fn which gets pending block request from the device queue and builds SCSI request from it. The request will be sent to the target device using the low level driver which controls specific storage device.
Cdrom/DVD Block Device
The SCSI cd-rom driver is implemented in drivers/scsi/sr.c . This is again block driver which works in similar fashion as the sd.c disk driver. Here again the sr_prep_fn will transform kernel block requests into scsi media commands which can be sent to the cd-rom device.
Generic Char Device
The generic SCSI device driver is implemented in drivers/scsi/sg.c. This is a catch all driver. It creates char device files with pattern /dev/sgxx to every SCSI device. Then it allows sending raw SCSI commands to the underlying SCSI devices using ioctl system call and specially crafted parameters. The popular sg3_utils package uses this driver to build extensive set of utilities that send SCSI commands to devices.
The SCSI Middle Layer
The SCSI middle layer is essentially a separation layer between the lower scsi layer and the rest of the kernel. It’s main role is to provide error handling and to allow low level drivers registration. SCSI commands coming from the higher device drivers will be registered and dispatched to the lower layer. Later when the lower layer sends commands to the device and receives response, this layer will propagate it back to the higher device drivers. If the command completes with error or if the response doesn’t arrive within some customizable timeout, retry and recovery steps will be taken by the midlayer. Such steps could mean asking to reset device or disabling it completely.
The SCSI Lower Layer
At the lowest layer of SCSI subsystem we have a collection of drivers which talk directly to the physical devices. Common interface to all these devices is used to connect them to the mid layer. On the other side the interaction with the device is performed by controlling physical interfaces using memory mapped I/O (MMIO), I/O CPU commands and interrupts mechanisms. The lower layer drivers family contains for example drivers provided by the leading fibre channel HBA vendors(Emulex, QLogic). Other drivers control RAIDs (for example LSI MegaRAID) SAS disks and etc.
Linux SCSI Target Frameworks
Linux kernel has rich support for connecting to various SCSI devices. When using such device Linux needs to implement the initiator role of the SCSI architecture. More and more new SCSI devices were introduced to the Linux kernel throughout the years. This lead to rapid improvement in the layers that supported SCSI initiator behavior. On the other hand the other side of the SCSI client-server architecture was neglected for many years. Since SCSI target code was built into the physical devices (e.g. disk drives) there was no particular reason to implement this layer in the Linux kernel.
With the introduction of virtualization technologies things started to change. Developers wanted to create custom SCSI devices and to expose existing storage elements on the local machine through the SCSI protocol. These requirements lead to creation of several SCSI target frameworks with unique design and implementation. Of these frameworks, LIO was eventually selected and on January 2011 [13] was merged into the kernel main line, effectively becoming the official framework for introducing SCSI target support into the Linux kernel.
LIO
LIO target framework is a recently new framework which was merged into the mainline kernel version 2.6.38 on 2011. The LIO framework provides access to most of the data storage devices over majority of the possible transport layers. LIO is maintained by Datera, Inc., a Silicon Valley vendor of storage systems and software.
LIO supports common storage fabrics, including
- FCoE,
- Fibre Channel,
- IEEE 1394,
- iSCSI,
- iSCSI Extensions for RDMA (iSER),
- SCSI RDMA Protocol (SRP)
- USB.
It is included in most Linux distributions; native support for LIO in QEMU/KVM, libvirt, and OpenStack makes LIO also a storage option for cloud deployments.
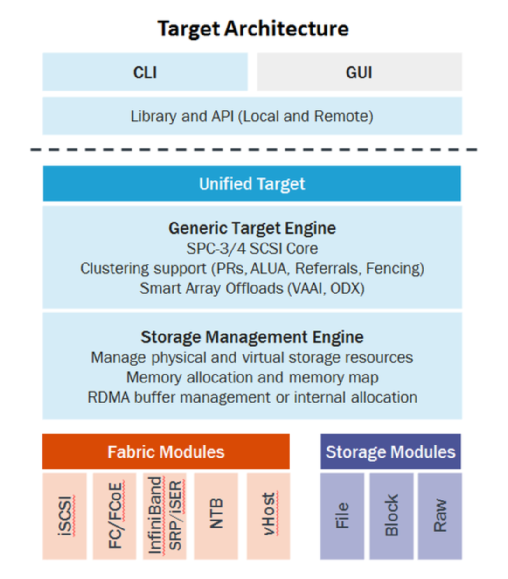
The architecture of the LIO consist of three main components:
- SCSI target engine - Implements the semantics of SCSI target without dependency of fabric (transport layer) or storage type
- Backstores - Backstore implements the back-end of the SCSI target device. It can be actual physical device, block device, file or memory disk
- Fabric modules - Fabric modules implement the front-end of the target. This is the part that communicates with initiator over transport layer. Between the implemented fabrics: iSCSI, Fibre Channel, iSER (iSCSI over infiniband) and etc.
Internally, LIO does not initiate sessions, but instead provides one or more Logical Unit Numbers (LUNs), waits for SCSI commands from a SCSI initiator, and performs required input/output data transfers.
Today LIO is a leading framework which replaced other frameworks(SCST, TGT) in the kernel main line. Nevertheless, time still needs to pass until the framework will become mature and stable for everyday use.