PREEMPT_RT Internals
Objectives:
- Allows preemption, so minimize latencies
- Execute all activities (including IRQ) in “schedulable/thread” context
Scheduling class
Introduce three real time scheduling classes:- deadline
- fifo
- rr(round robin,fifo with weights)
Please refer "Scheduler" chapter for details.

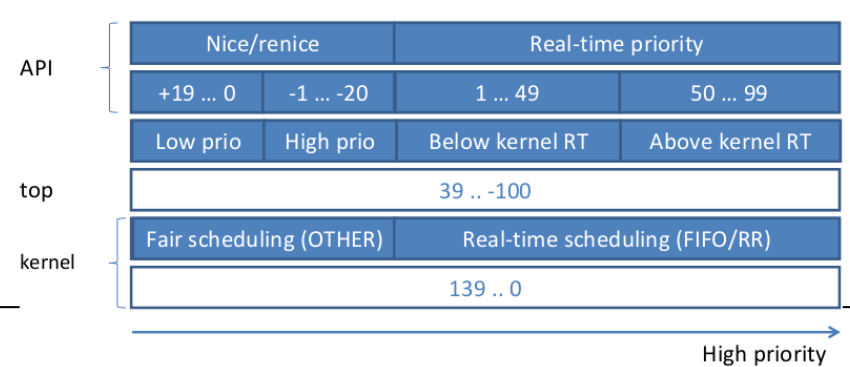
Two separate priority ranges
- Nice value: -20 ... +19 (19 being the lowest)
- Real-time priority: 0 ... 99 (higher value is higher prio)
- ps priority: 0 ... 139 (0: lowest and 139: highest)
Programming Interface
sched_setscheduler() API can be used to change the scheduling class and priority of a process
int sched_setscheduler(pid_t pid, int
policy, const struct sched_param *param);
policy can be SCHED_OTHER, SCHED_FIFO,
SCHED_RR, etc.
param is a structure containing the priority
Priority can be set on a per-thread basis when its creation:
struct sched_param parm;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setinheritsched(&attr,
PTHREAD_EXPLICIT_SCHED);
pthread_attr_setschedpolicy(&attr, SCHED_FIFO);
parm.sched_priority = 42;
pthread_attr_setschedparam(&attr, &parm);
Latencies
The time between an event is expected to occur and the time it actually does is called latency. The event may be an external stimulus that wants a response, or a thread that has just woken up and needs to be scheduled. The following is the different kinds and causes of latencies and these terms will be used later in this paper.
- Interrupt Latency — The time between an interrupt triggering and when it is actually ser- viced.
- Wakeup Latency — The time between the highest priority task being woken up and the time it actually starts to run. This also can be called Scheduling Latency.
- Priority Inversion — The time a high pri- ority thread must wait for a resource owned by a lower priority thread.
- Interrupt Inversion — The time a high priority thread must wait for an interrupt to perform a task that is of lower priority.
Threaded Interrupts(2.6)
Interrupt can be executed by a kernel thread, we can assign a priority to each thread.
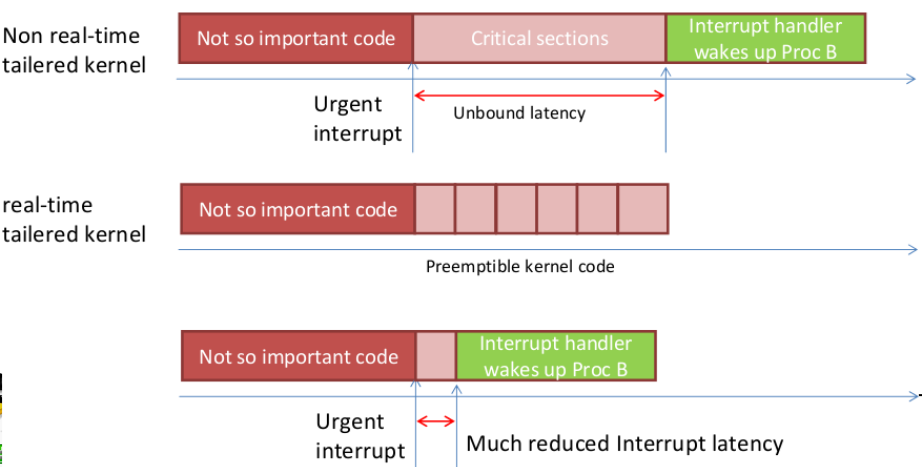
As mentioned in Section 1.1, one of the causes of la- tency involves interrupts servicing lower priority tasks. A high priority task should not be greatly affected by a low priority task, for example, doing heavy disk IO. With the normal interrupt handling in the mainline ker- nel, the servicing of devices like hard-drive interrupts can cause large latencies for all tasks. The RT patch uses threaded interrupt service routines to address this issue.
When a device driver requests an IRQ, a thread is cre- ated to service this interrupt line. Only one thread can be created per interrupt line. Shared interrupts are still handled by a single thread. The thread basically per- forms the following:
while (!kthread_should_stop()) {
set_current_state(TASK_INTERRUPTIBLE);
do_hardirq(desc);
cond_resched();
schedule();
}
RT-Mutexes(2.6)
RT-mutexes extend the semantics of simple mutexes by the priority inheritance protocol.
BKL-free(2.6)
Since 2.6.37 kernel can be built completely without the use of Big Kernel Lock.
preemption options(2.6)
Priority inheritance(2.6.18)
- Implemented in kernel space locking.
- Available in user space locking too, through fast user-space mutexes (“futex”).
- kernel documentation:
- Documentation/pifutex.txt
- Documentation/rtmutexdesign.txt
Priority inheritance must be activated explicitly
pthread_mutexattr_t attr;
pthread_mutexattr_init (&attr);
pthread_mutexattr_getprotocol(&attr,PTHREAD_PRIO_INHERIT);
High-resolution timers(2.6.21)
Make it possible for POSIX timers and nanosleep() to be as accurate as allowed by the hardware (typically 1 us). Together with tickless support, allow for “on-demand” timer interrupts.
PREEMPT_RT
Clarify first
The primary goal is to make the system predictable and deterministic.
- It will NOT improve throughput and overall performance, instead, it will degrade overall performance.
- You cannot say it ALWAYS reduce latency, often it's opposite. But the maximum latency will be reduced.
- Linux RT patches are not mainstream yet. There is resistance to retain the general purpose nature of Linux.
- Though they are preemptible, kernel services (such as memory allocation) do not have a guaranteed latency yet! However, not really a problem: real-time applications should allocate all their resources ahead of time.
- Kernel drivers are not developed for real-time constraints yet (e.g. USB or PCI bus stacks).
- Binary-only drivers have to be recompiled for RT preempt
- Memory management (SLOB/SLUB allocator) still runs with preemption disabled for long periods of time
- Lock around per-CPU data accesses, eliminating the preemption problem but wrecking scalability
Implementation
Overview
Classic Kernel

Preempt Kernel

Preempt as much as possible
Make OS preemptible as much as possible, except preempt_disable and interrupt disable
Threaded IRQ
Make Threaded (schedulable) IRQs so that it can be scheduled
Sleeping spinlock
spinlocks converted to mutexes (a.k.a. sleeping spinlocks)
- Not disabling interrupt and allows preemption
- Works well with threaded interrupts
Interface Changes
- spinlocks and local_irq_save() no longer disable hardware interrupts.
- spinlocks no longer disable preemption.
- Raw_ variants for spinlocks and local_irq_save() preserve original meaning for SO_NODELAY interrupts.
- Semaphores and spinlocks employ priority inheritance
Timer Frequency
100HZ -> 1000HZ
High Resolution Timer
- Use non-RTC interrupt timer sources to deliver timer interrupt between ticks.
- Allows POSIX timers and nanosleep() to be as accurate as the hardware allows.
- This feature is transparent.
- When enabled it makes these timers much more accurate than the current HZ resolution.
- Around 1usec on typical hardware.
const int NSEC_IN_SEC = 1000000000l, INTERVAL = 1000000l; struct timespec timeout; clock_gettime(CLOCK_MONOTONIC, &timeout); while (1) { do_some_work(&some_data); timeout.tv_nsec += INTERVAL; if (timeout.tv_nsec >= NSEC_IN_SEC) { timeout.tv_nsec = NSEC_IN_SEC; timeout.tv_sec++; } clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &timeout, NULL); }
mlock for emand paging latency
Locking pages in RAM, A solution to latency issues with demand paging
- mlock: Lock a given region of process address space in RAM. Makes sure that this region is always loaded in RAM.
- mlockall Lock the whole process address space.
- munlock, munlockall Unlock a part or all of the process address space.