Idle Scheduling Class
In the last post I said the fundamental axiom of OS behavior is that at any given time, exactly one and only one task is active on a CPU. But if there’s absolutely nothing to do, then what?
It turns out that this situation is extremely common, and for most personal computers it’s actually the norm: an ocean of sleeping processes, all waiting on some condition to wake up, while nearly 100% of CPU time is going into the mythical “idle task.” In fact, if the CPU is consistently busy for a normal user, it’s often a misconfiguration, bug, or malware.
OS developers create an idle task that gets scheduled to run when there’s no other work. We have seen in the Linux boot process that the idle task is process 0, a direct descendent of the very first instruction that runs when a computer is first turned on. It is initialized in rest_init, where init_idle_bootup_task initializes the idle scheduling class.
Briefly, Linux supports different scheduling classes for things like real-time processes, regular user processes, and so on. When it’s time to choose a process to become the active task, these classes are queried in order of priority. That way, the nuclear reactor control code always gets to run before the web browser. Often, though, these classes return NULL, meaning they don’t have a suitable process to run – they’re all sleeping. But the idle scheduling class, which runs last, never fails: it always returns the idle task.
That’s all good, but let’s get down to just what exactly this idle task is doing. So here is cpu_idle_loop, courtesy of open source:
while (1) {
while(!need_resched()) {
cpuidle_idle_call();
}
/*
[Note: Switch to a different task. We will return to this loop when the
idle task is again selected to run.]
*/
schedule_preempt_disabled();
}
I’ve omitted many details, and we’ll look at task switching closely later on, but if you read the code you’ll get the gist of it: as long as there’s no need to reschedule, meaning change the active task, stay idle. Measured in elapsed time, this loop and its cousins in other OSes are probably the most executed pieces of code in computing history. For Intel processors, staying idle traditionally meant running the halt instruction:
static inline void native_halt(void)
{
asm volatile("hlt": : :"memory");
}
hlt stops code execution in the processor and puts it in a halted state. It’s weird to think that across the world millions and millions of Intel-like CPUs are spending the majority of their time halted, even while they’re powered up. It’s also not terribly efficient, energy wise, which led chip makers to develop deeper sleep states for processors, which trade off less power consumption for longer wake-up latency. The kernel’s cpuidle subsystem is responsible for taking advantage of these power-saving modes.
Now once we tell the CPU to halt, or sleep, we need to somehow bring it back to life. If you’ve read the last post, you might suspect interrupts are involved, and indeed they are. Interrupts spur the CPU out of its halted state and back into action. So putting this all together, here’s what your system mostly does as you read a fully rendered web page:
 Other interrupts besides the timer interrupt also get the processor moving again. That’s what happens if you click on a web page, for example: your mouse issues an interrupt, its driver processes it, and suddenly a process is runnable because it has fresh input. At that point need_resched() returns true, and the idle task is booted out in favor of your browser.
Other interrupts besides the timer interrupt also get the processor moving again. That’s what happens if you click on a web page, for example: your mouse issues an interrupt, its driver processes it, and suddenly a process is runnable because it has fresh input. At that point need_resched() returns true, and the idle task is booted out in favor of your browser.
But let’s stick to idleness in this post. Here’s the idle loop over time:
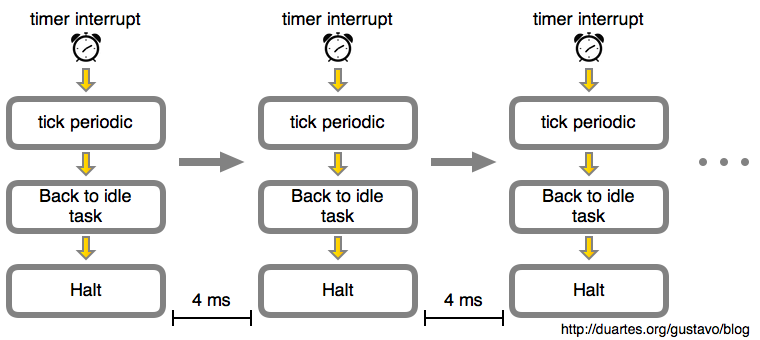 In this example the timer interrupt was programmed by the kernel to happen every 4 milliseconds (ms). This is the tick period. That means we get 250 ticks per second, so the tick rate or tick frequency is 250 Hz. That’s a typical value for Linux running on Intel processors, with 100 Hz being another crowd favorite. This is defined in the CONFIG_HZ option when you build the kernel.
In this example the timer interrupt was programmed by the kernel to happen every 4 milliseconds (ms). This is the tick period. That means we get 250 ticks per second, so the tick rate or tick frequency is 250 Hz. That’s a typical value for Linux running on Intel processors, with 100 Hz being another crowd favorite. This is defined in the CONFIG_HZ option when you build the kernel.
Now that looks like an awful lot of pointless work for an idle CPU, and it is. Without fresh input from the outside world, the CPU will remain stuck in this hellish nap getting woken up 250 times a second while your laptop battery is drained. If this is running in a virtual machine, we’re burning both power and valuable cycles from the host CPU.
The solution here is to have a dynamic tick so that when the CPU is idle, the timer interrupt is either deactivated or reprogrammed to happen at a point where the kernel knows there will be work to do (for example, a process might have a timer expiring in 5 seconds, so we must not sleep past that). This is also called tickless mode.
Finally, suppose you have one active process in a system, for example a long-running CPU-intensive task. That’s nearly identical to an idle system: these diagrams remain about the same, just substitute the one process for the idle task and the pictures are accurate. In that case it’s still pointless to interrupt the task every 4 ms for no good reason: it’s merely OS jitter slowing your work ever so slightly. Linux can also stop the fixed-rate tick in this one-process scenario, in what’s called adaptive-tick mode. Eventually, a fixed-rate tick may be gone altogether.
NO_HZ: Reducing Scheduling-Clock Ticks
There are three main ways of managing scheduling-clock interrupts (also known as "scheduling-clock ticks" or simply "ticks"):
Never omit scheduling-clock ticks (CONFIG_HZ_PERIODIC=y or CONFIG_NO_HZ=n for older kernels). You normally will -not- want to choose this option.
Omit scheduling-clock ticks on idle CPUs (CONFIG_NO_HZ_IDLE=y or CONFIG_NO_HZ=y for older kernels). This is the most common approach, and should be the default.
Omit scheduling-clock ticks on CPUs that are either idle or that have only one runnable task (CONFIG_NO_HZ_FULL=y). Unless you are running realtime applications or certain types of HPC workloads, you will normally -not- want this option.
tickless/dynamic tick
If a CPU is idle, there is little point in sending it a scheduling-clock interrupt. After all, the primary purpose of a scheduling-clock interrupt is to force a busy CPU to shift its attention among multiple duties, and an idle CPU has no duties to shift its attention among.
The CONFIG_NO_HZ_IDLE=y Kconfig option causes the kernel to avoid sending scheduling-clock interrupts to idle CPUs, which is critically important both to battery-powered devices and to highly virtualized mainframes. A battery-powered device running a CONFIG_HZ_PERIODIC=y kernel would drain its battery very quickly, easily 2-3 times as fast as would the same device running a CONFIG_NO_HZ_IDLE=y kernel. A mainframe running 1,500 OS instances might find that half of its CPU time was consumed by unnecessary scheduling-clock interrupts. In these situations, there is strong motivation to avoid sending scheduling-clock interrupts to idle CPUs. That said, dyntick-idle mode is not free:
It increases the number of instructions executed on the path to and from the idle loop.
On many architectures, dyntick-idle mode also increases the number of expensive clock-reprogramming operations.
Therefore, systems with aggressive real-time response constraints often run CONFIG_HZ_PERIODIC=y kernels (or CONFIG_NO_HZ=n for older kernels) in order to avoid degrading from-idle transition latencies.
In this kind of "tickless" kernels, there is no fixed timer tick. Instead, the kernel schedules the next timer tick in response to its next event. Perhaps a better name is a "dynamic tick" kernel. If the running process has 18 milliseconds of timeslice left, then the kernel can dynamically schedule the timer interrupt for 18 milliseconds from now. This allows the system to negate the tradeoffs of a fixed interval: High frequency when you need the granularity, low frequency when you don't. Moreover, if the system is idle, there is no reason to schedule a periodic timer tick at all. The system can go truly idle, vastly improving battery life.
The cons are complexity. A tick-based system is significantly simpler than a tickless one. As a programmer, it is much easier to develop kernel code where you know there is some fixed frequency to the timer interrupt and you can rely on the tick to always hit at that interval. On a system such as Linux that supports tickless operation you are more-or-less paying the cost whether or not you enable the feature. The major cost to turning a tickless system on is computation of the dynamic tick and the rescheduling of timers. For most workloads, this is negligible.