GPU and deep learning
GeePS
Large-scale deep learning requires huge computational re- sources to train a multi-layer neural network. Recent systems propose using 100s to 1000s of machines to train networks with tens of layers and billions of connections. While the computation involved can be done more efficiently on GPUs than on more traditional CPU cores, training such networks on a single GPU is too slow and training on distributed GPUs can be inefficient, due to data movement overheads, GPU stalls, and limited GPU memory. This paper describes a new parameter server, called GeePS, that supports scalable deep learning across GPUs distributed among multiple machines, overcoming these obstacles. We show that GeePS enables a state-of-the-art single-node GPU implementation to scale well, such as to 13 times the number of training images pro- cessed per second on 16 machines (relative to the original optimized single-node code). Moreover, GeePS achieves a higher training throughput with just four GPU machines than that a state-of-the-art CPU-only system achieves with 108 machines.
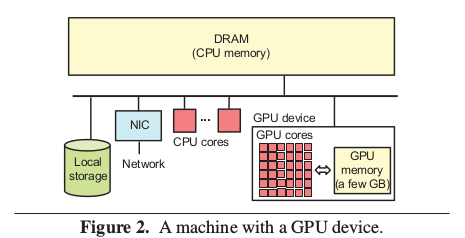
Deep learning using GPUs GPUs are often used to train deep neural networks, be- cause the primary computational steps match their single- instruction-multiple-data (SIMD) nature and they provide much more raw computing capability than traditional CPU cores. Most high end GPUs are on self-contained devices that can be inserted into a server machine, as illustrated in Figure 2. One key aspect of GPU devices is that they have dedicated local memory, which we will refer to as “GPU memory,” and their computing elements are only efficient when working on data in that GPU memory. Data stored out- side the device, in CPU memory, must first be brought into the GPU memory (e.g., via PCI DMA) for it to be accessed efficiently.
 Neural network training is an excellent match to the GPU
computing model. For example, the forward pass of a fully
connected layer, for which the value of each output node
is calculated as the weighted sum of all input nodes, can
be expressed as a matrix-matrix multiplication for a whole
mini-batch. During the backward pass, the error terms and
gradients can also be computed with similar matrix-matrix
multiplications. These computations can be easily decom-
posed into SIMD operations and be performed efficiently with
the GPU cores. Computations of other layers, such as con-
volution, have similar SIMD properties and are also efficient
on GPUs. NVIDIA provides libraries for launching these
computations on GPUs, such as the cuBLAS library [1] for
basic linear algebra computations and the cuDNN library [2]
for neural-network specific computations (e.g., convolution).
Neural network training is an excellent match to the GPU
computing model. For example, the forward pass of a fully
connected layer, for which the value of each output node
is calculated as the weighted sum of all input nodes, can
be expressed as a matrix-matrix multiplication for a whole
mini-batch. During the backward pass, the error terms and
gradients can also be computed with similar matrix-matrix
multiplications. These computations can be easily decom-
posed into SIMD operations and be performed efficiently with
the GPU cores. Computations of other layers, such as con-
volution, have similar SIMD properties and are also efficient
on GPUs. NVIDIA provides libraries for launching these
computations on GPUs, such as the cuBLAS library [1] for
basic linear algebra computations and the cuDNN library [2]
for neural-network specific computations (e.g., convolution).
Caffe [21] is an open-source deep learning system that
uses GPUs. In Caffe, a single-threaded worker launches and
joins with GPU computations, by calling NVIDIA cuBLAS
and cuDNN libraries, as well as some customized CUDA
kernels. Each mini-batch of training data is read from an
input file via the CPU, moved to GPU memory, and then
processed as described above. For efficiency, Caffe keeps all
model parameters and intermediate states in the GPU memory.
As such, it is effective only for models and mini-batches small
enough to be fully held in GPU memory. Figure 3 illustrates
the CPU and GPU memory usage for a basic Caffe scenario.

Scaling ML with a parameter server
While early parallel ML implementations used direct message passing (e.g., via MPI) among threads for update exchanges, a parameter server architecture has become a popular approach to making it easier to build and scale ML applications across CPU-based clusters [3, 4, 7, 10, 11, 14, 19, 25, 31, 36], particularly for data-parallel execution. Indeed, two of the largest efforts to address deep learning have used this architecture [7, 14].
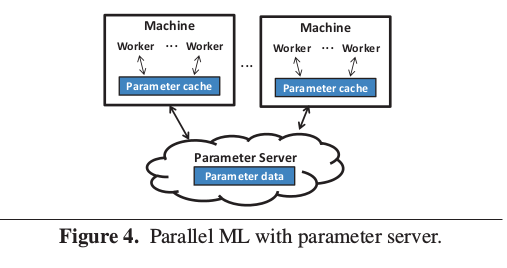
Figure 4 illustrates the basic parameter server architec-
ture. All state shared among application workers (i.e., the
model parameters being learned) is kept in distributed shared
memory implemented as a specialized key-value store called
a “parameter server”. An ML application’s workers process
their assigned input data and use simple Read and Update
methods to fetch or apply a delta to parameter values, leaving
the communication and consistency issues to the parameter
server. The value type is often application defined, but is re-
quired to be serializable and be defined with an associative
and commutative aggregation function, such as plus or multi-
ply, so that updates from different workers can be applied in
any order. In our image classification example, the value type
could be an array of floating point values and the aggregation
function could be plus.
 To reduce remote communication, a parameter server sys-
tem includes client-side caches that serve most operations
locally. While some systems rely entirely on best-effort asyn-
chronous propagation of parameter updates, many include an
explicit Clock method to identify a point (e.g., the end of an
iteration or mini-batch) at which a worker’s cached updates
should be pushed to the shared key-value store and its local
cache state should be refreshed. The consistency model can
conform to the Bulk Synchronous Parallel (BSP) model, in
which all updates from the previous clock must be visible
before proceeding to the next clock, or can use a looser but
still bounded model. For example, the Stale Synchronous
Parallel (SSP) model [10, 19] allows the fastest worker to be
ahead of the slowest worker by a bounded number of clocks.
Both models have been shown to converge, experimentally
and theoretically, with different tradeoffs.
To reduce remote communication, a parameter server sys-
tem includes client-side caches that serve most operations
locally. While some systems rely entirely on best-effort asyn-
chronous propagation of parameter updates, many include an
explicit Clock method to identify a point (e.g., the end of an
iteration or mini-batch) at which a worker’s cached updates
should be pushed to the shared key-value store and its local
cache state should be refreshed. The consistency model can
conform to the Bulk Synchronous Parallel (BSP) model, in
which all updates from the previous clock must be visible
before proceeding to the next clock, or can use a looser but
still bounded model. For example, the Stale Synchronous
Parallel (SSP) model [10, 19] allows the fastest worker to be
ahead of the slowest worker by a bounded number of clocks.
Both models have been shown to converge, experimentally
and theoretically, with different tradeoffs.
While the picture illustrates the parameter server as sepa- rate from the machines executing worker threads, and some systems do work that way, the server-side parameter server state is commonly sharded across the same machines as the worker threads. The latter approach is particularly appro- priate when considering a parameter server architecture for GPU-based ML execution, since the CPU cores and CPU memory is otherwise used only for input data buffering and preparation.
Given its proven value in CPU-based distributed ML, it
is natural to use the same basic architecture and program-
ming model with distributed ML on GPUs. To explore its
effectiveness, we ported two applications (the Caffe system
discussed above and a multi-class logistic regression (MLR)
program) to a state-of-the-art parameter server system (Iter-
Store [11]). Doing so was straightforward and immediately
enabled distributed deep learning on GPUs, confirming the
application programmability benefits of the data-parallel pa-
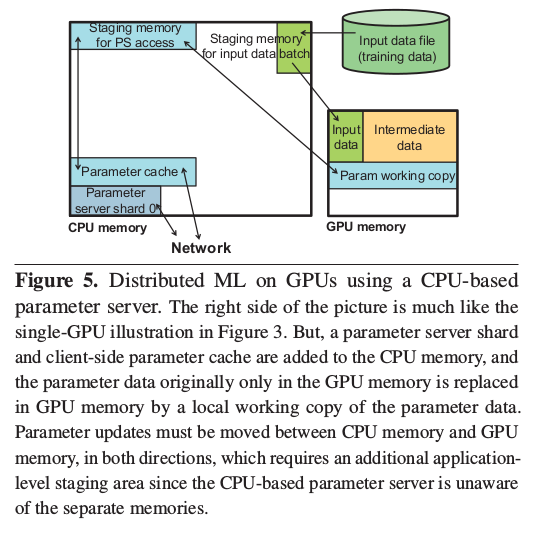
rameter server approach. Figure 5 illustrates what sits where
in memory, to allow comparison to Figure 3 and designs
described later.
 While it was easy to get working, the performance was not
acceptable. As noted by Chilimbi et al. [7], the GPU’s com-
puting structure makes it “extremely difficult to support data
parallelism via a parameter server” using current implementa-
tions, because of GPU stalls, insufficient synchronization/con-
sistency, or both. Also as noted by them and others [30, 33],
the need to fit the full model, as well as a mini-batch of input
data and intermediate neural network states, in the GPU mem-
ory limits the size of models that can be trained.
While it was easy to get working, the performance was not
acceptable. As noted by Chilimbi et al. [7], the GPU’s com-
puting structure makes it “extremely difficult to support data
parallelism via a parameter server” using current implementa-
tions, because of GPU stalls, insufficient synchronization/con-
sistency, or both. Also as noted by them and others [30, 33],
the need to fit the full model, as well as a mini-batch of input
data and intermediate neural network states, in the GPU mem-
ory limits the size of models that can be trained.
GPU-specialized parameter server design
This section describes three primary specializations to a parameter server to enable efficient support of parallel ML applications running on distributed GPUs:
- explicit use of GPU memory for the parameter cache,
- batch-based parameter access methods, and
- parameter server management of GPU memory on behalf of the application.
The first two address performance, and the third expands the range of problem sizes that can be addressed with data-parallel execution on GPUs. Also discussed is the topic of execution model synchrony, which empirically involves a different choice for data-parallel GPU-based training than for CPU-based training.