Nvdimm
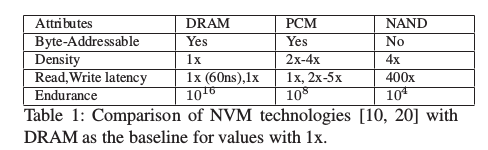
Byte-addressable NVMs such as PCM, Memristor,and 3D XPoint, are expected to provide 100x faster read and write performance compared to current SSDs. These NVMs are expected to scale 2-4x more than DRAM because they store multiple bits per cell without using refresh power and have known limitations imposed by an endurance of a few million writes per cell.
Further, they can be connected to the memory bus, and accessed using load and store operations.
Researchers have explored different usage models for the capacity and persistence use of NVM. Early NVM system software and hardware research studied the feasibility of using NVMs as a data cache for additional memory capacity that is transparent to the application. These studies do not use NVMs for persistent storage.
Recent software solutions have redesigned the block-based filesystem to suit the memory-based storage by extending the VFS data structures. In contrast, research proposals such as Mnemosyne, NVHeaps, and Aerie have extended the ideas of the well-known LRVM work to support heap-based persistence. Interestingly, all current heap-based proposals are managed by the VFS.
In contrast, pVM manages the NVM by extending the VM subsystem instead of the VFS. Our solution lets the system and applications use NVM both for capacity and for heap-based object storage. For comparison, we use Intel’s PMFS as the state-of-the-art solution due to several OS-level optimizations and its wide acceptance in the NVM research community. We also evaluate other approaches such as Mnemosyne and ramFS.
NVDIMM Support in Linux
There are four usage models:
- Use it as cache: Memblaze
- Use it as a block device: lRVM, Mnemosyne
- Filesystem support persistent memory .
- DAX.
- Intel PMFS, ramFS.
- Use it as main memory -- pVM.
pVM
persistent Virtual Memory (pVM), explores an alternate approach that extends the virtual memory (VM) subsystem, instead of the VFS, for achieving the dual bene- fits of memory capacity scaling and persistent storage using NVMs. pVM’s design is based on the principle that byte- addressable NVMs resemble ‘slower’ memory placed in par- allel to DRAM with the memory bus as a hardware interface, rather than a faster disk. Hence, extending the virtual mem- ory (VM) subsystem is better suited to more efficiently ex- ploit NVMs for both capacity and persistent object storage. pVM is not a replacement for traditional filesystems and has been specifically designed for the use of NVM for scaling memory and providing a persistent object store. To the best of our knowledge, pVM is the first OS-based design that ex- tends the VM subsystem to provide such dual-use.
pVM’s OS hardware abstraction treats NVM as a NUMA node to which applications can transparently or explicitly allocate additional heap memory, as well as store persis- tent objects by using user space memory persistence li- braries [39, 40]. This generic NUMA node-based design can support several NVM nodes, permit seamless scaling of memory capacity across the nodes, and provide applications with flexible NVM-specific memory placement policies that can be easily integrated with existing memory placement libraries. Unlike the VFS-based approach that maps both persistent and non-persistent allocations to a file, pVM’s OS virtual memory framework distinguishes between per- sistent and non-persistent memory (page) allocations and manages them independently without adding any persistent metadata management cost for capacity (heap) allocations. This significantly reduces page access time and cache and TLB misses, which is critical for applications’ performance and helps mitigate NVMs’ higher device access cost when compared to DRAM (see Table 1).
pVM also extends the VM subsystem with persistence management. This avoids the metadata complexity of a block-based filesystem and the overheads of kernel me- diation from using a POSIX interface, which leads to re- duced time spent in the OS. With pVM, persistent objects are mapped to a region of NVM pages that can be retrieved across application sessions. Performance of the persistent object store is improved with pVM due to fast on-demand page allocations and efficient TLB and cache use. pVM is designed for object stores with flat namespaces, such as NoSQL databases, personal user data, search engines, key- value stores, etc., and thus may not be a good fit for ap- plications with significant dependence on the hierarchical filesystem. Hence, we envision that pVM’s object store will coexist with a standard block-based NVM filesystem.
pVM makes the following technical contributions:
- End-to-end persistent virtual memory design – We pro- pose persistent virtual memory (pVM), an end-to-end vir- tual memory-based design that treats NVM as a memory node (similar to NUMA) and extends the OS VM subsys- tem for memory capacity scaling, and fast and persistent object stores. (Section 3)
- Memory capacity scaling and placement support – We demonstrate several benefits of pVM’s VM-based design, such as automatic memory capacity scaling, support for flexible NVM data placement policies that are compat- ible with existing NUMA-based libraries, fast page ac- cess, and improved processor cache and TLB efficiency when compared to state-of-the-art VFS-based designs. (Section 4)
- Fast persistent object storage – We extend the VM data structures with support for persistence, and thereby pro- vide fast, consistent, and durable object storage. This mechanism significantly reduces the time spent in the kernel and improves the object store throughput. (Sec- tion 4)
- Evaluation and performance – Our evaluation shows a 2.5x reduction in application runtime with automatic memory capacity scaling, up to a 28% reduction in cache and TLB misses for benchmarks, 84% cache and TLB miss reductions for applications, and 60% reductions in page access cost. Further, pVM-based object store im- proves application throughput by 52%-100% relative to a VFS block-based design, with up to 4x reduction in the time spent in the OS. (Section 5)
DAX
For a few years now, we have been told that upcoming non-volatile memory (NVM) devices are going to change how we use our systems. These devices provide large amounts (possibly terabytes) of memory that is persistent and that can be accessed at RAM speeds. Just what we will do with so much persistent memory is not entirely clear, but it is starting to come into focus. It seems that we'll run ordinary filesystems on it — but those filesystems will have to be tweaked to allow users to get full performance from NVM.
It is easy enough to wrap a block device driver around an NVM device and make it look like any other storage device. Doing so, though, forces all data on that device to be copied to and from the kernel's page cache. Given that the data could be accessed directly, this copying is inefficient at best. Performance-conscious users would rather avoid use of the page cache whenever possible so that they can get full-speed performance out of NVM devices.
The kernel has actually had some support for direct access to non-volatile memory since 2005, when execute-in-place (XIP) support was added to the ext2 filesystem. This code allows files from a directly-addressable device to be mapped into user space, allowing file data to be accessed without going through the page cache. The XIP code has apparently seen little use, though, and has not been improved in some years; it does not work with current filesystems.
Last year, Matthew Wilcox began work on improving the XIP code and integrating it into the ext4 filesystem. Along the way, he found that it was not well suited to the needs of contemporary filesystems; there are a number of unpleasant race conditions in the code as well. So over time, his work shifted from enhancing XIP to replacing it. That work, currently a 21-part patch set, is getting closer to being ready for merging into the mainline, so it is beginning to get a bit more attention.
Those patches replace the XIP code with a new subsystem called DAX (for "direct access," apparently). At the block device level, it replaces the existing direct_access() function in struct block_device_operations with one that looks like this:
long (*direct_access)(struct block_device *dev, sector_t sector,
void **addr, unsigned long *pfn, long size);
This function accepts a sector number and a size value saying how many bytes the caller wishes to access. If the given space is directly addressable, the base (kernel) address should be returned in addr and the appropriate page frame number goes into pfn. The page frame number is meant to be used in page tables when arranging direct user-space access to the memory.
The use of page frame numbers and addresses may seem a bit strange; most of the kernel deals with memory at this level via struct page. That cannot be done here, though, for one simple reason: non-volatile memory is not ordinary RAM and has no page structures associated with it. Those missing page structures have a number of consequences; perhaps most significant is the fact that NVM cannot be passed to other devices for DMA operations. That rules out, for example, zero-copy network I/O to or from a file stored on an NVM device. Boaz Harrosh is working on a patch set allowing page structures to be used with NVM, but that work is in a relatively early state.
Moving up the stack, quite a bit of effort has gone into pushing NVM support into the virtual filesystem layer so that it can be used by all filesystems. Various generic helpers have been set up for common operations (reading, writing, truncating, memory-mapping, etc.). For the most part, the filesystem need only mark DAX-capable inodes with the new S_DAX flag and call the helper functions in the right places; see the documentation in the patch set for (a little) more information. The patch set finishes by adding the requisite support to ext4.
Andrew Morton expressed some skepticism about this work, though. At the top of his list of questions was: why not use a "suitably modified" version of an in-memory filesystem (ramfs or tmpfs, for example) instead? It seems like a reasonable question; those filesystems are already designed for directly-addressable memory and have the necessary optimizations. But RAM-based filesystems are designed for RAM; it turns out that they are not all that well suited to the NVM case.
For the details of why that is, this message from Dave Chinner is well worth reading in its entirety. To a great extent, it comes down to this: the RAM-based filesystems have not been designed to deal with persistence. They start fresh at each boot and need never cope with something left over from a previous run of the system. Data stored in NVM, instead, is expected to persist over reboots, be robust in the face of crashes, not go away when the kernel is upgraded, etc. That adds a whole set of requirements that RAM-based filesystems do not have to satisfy.
So, for example, NVM filesystems need all the tools that traditional filesystems have to recognize filesystems on disk, check them, deal with corruption, etc. They need all of the techniques used by filesystems to ensure that the filesystem image in persistent storage is in a consistent state at all times; metadata operations must be carefully ordered and protected with barriers, for example. Since compatibility with different kernels is important, no in-kernel data structures can be directly stored in the filesystem; they must be translated to and from an on-disk format. Ordinary filesystems do these things; RAM-based filesystems do not.
Then, as Dave explained, there is the little issue of scalability:
Further, it's going to need to scale to very large amounts of storage. We're talking about machines with tens of TB of NVDIMM capacity in the immediate future and so free space management and concurrency of allocation and freeing of used space is going to be fundamental to the performance of the persistent NVRAM filesystem. So, you end up with block/allocation groups to subdivide the space. Looking a lot like ext4 or XFS at this point. And now you have to scale to indexing tens of millions of everything. At least tens of millions - hundreds of millions to billions is more likely, because storing tens of terabytes of small files is going to require indexing billions of files. And because there is no performance penalty for doing this, people will use the filesystem as a great big database. So now you have to have a scalable posix compatible directory structures, scalable freespace indexation, dynamic, scalable inode allocation, freeing, etc. Oh, and it also needs to be highly concurrent to handle machines with hundreds of CPU cores. Dave concluded by pointing out that the kernel already has a couple of "persistent storage implementations" that can handle those needs: the XFS and ext4 filesystems (though he couldn't resist poking at the scalability of ext4). Both of them will work now on a block device based on persistent memory. The biggest thing that is missing is a way to allow users to directly address all of that data without copying it through the page cache; that is what the DAX code is meant to provide.
There are groups working on filesystems designed for NVM from the beginning. But most of that work is in an early stage; none has been posted to the kernel mailing lists, much less proposed for merging. So users wanting to get full performance out of NVM will find little help in that direction for some years yet. It is thus not unreasonable to conclude that there will be some real demand for the ability to use today's filesystems with NVM systems.
The path toward that capability would appear to be DAX. All that is needed is to get the patch set reviewed to the point that the relevant subsystem maintainers are comfortable merging it. That review has been somewhat slow in coming; the patch set is complex and touches a number of different subsystems. Still, the code has changed considerably in response to the reviews that have come in and appears to be getting close to a final state. Perhaps this functionality will find its way into the mainline in a near-future development cycle.
Memblaze
Zhongjie Wu is working at Memblaze, a famous startup company in China on flash storage technology. Zhongjie showed us one of their products on top of NVDIMM. An NVDIMM is not expensive, it is only a DDR DIMM with a capacitor.
Memblaze has developed a new 1U storage server with a NVDIMM (as a write cache) and many flash cards (as the backend storage). It contains their own developed OS and could use Fabric-Channel/Ethernet to connect to client.
The main purpose of NVDIMM is to reduce latency, and they use write-back strategy. Zhongjie also mentioned that NVDIMM's write performance is quite better than its read performance, so they in fact uses shadow memory to increase read performance.
The big problem they face with NVDIMM is CPU can’t flush data in its L1 cache to NVDIMM when whole server powers down. To solve this problem, Memblaze use write-combining in CPU multi-cores, it hurts the performance a little but avoid the data missing finally.
What is write combining
WRITE COMBINING Once a memory region has been defined as having the WC memory type, accesses into the memory region will be subject to the architectural definition of WC:
WC is a weakly ordered memory type. System memory locations are not cached and coherency is not enforced by the processor’s bus coherency protocol. Speculative reads are allowed. Writes may be delayed and combined in the write combining buffer to reduce memory accesses..
What does this really mean? Writes to WC memory are not cached in the typical sense of the word cached. They are delayed in an internal buffer that is separate from the internal L1 and L2 caches. The buffer is not snooped and thus does not provide data coherency. The write buffering is done to allow software a small window of time to supply more modified data to the buffer while remaining as non-intrusive to software as possible. The size of the buffer is not defined in the architectural statement above. The Pentium Pro processor and Pentium II processor implement a 32 byte buffer. The size of this buffer was chosen by implementation convenience rather than by performance optimization. The buffer size optimization process may occur in a future generation of the P6 family processor and so software should not rely upon the current 32 byte WC buffer size or the existence of just a single concurrent buffer. The WC buffering of writes has another facet, data is also collapsed e.g. multiple writes to the same location will leave the last data written in the location and the other writes may be lost.
More Explanations
Most memory you deal with on a daily basis is cached; on CPUs, it’s usually write-back cached. While dealing with processor caches can be counter-intuitive, caching works well most of the time, and it’s mostly transparent to the programmer (and certainly the user). However, if we are to use the cache to service memory reads, we need to make sure to invalidate our cache entries if someone else writes to the corresponding memory locations. This is implemented using one of several mechanisms referred to as “coherency protocols”, which CPU cores use to synchronize their caches with each other.
Because while such mechanisms are in place for CPUs talking to each other, there is nothing equivalent for the CPU talking to other non-CPU devices, such as GPUs, storage or network devices. Generally, communication with such devices still happens via system memory (or by memory-mapping registers or device memory so they appear to be system memory, which doesn’t make much difference from the CPU core’s point of view), but the CPU is not going to be notified of changes in a timely fashion, so normal caching is out.
Originally, device memory used to be accessed completely without caching. That’s safe (or at least as safe as it’s going to get) but also slow, because each memory access gets turned into an individual bus transaction, which has considerable overhead. Now anything related to graphics tends to move a lot of data around. Before widespread hardware acceleration, it was mostly the CPU writing pixels to the frame buffer, but now there’s other graphics-related writes too.
So finally we get write combining, where the CPU treats reads as uncached but will buffer writes for a while in the hope of being able to combine multiple adjacent writes into a larger bus transaction. This is much faster.
Common implementations have much weaker memory ordering guarantees than most memory accesses, but that’s fine too; this kind of thing tends to be used mainly for bulk transfers, where you really don’t care in which order the bytes trickle into memory. All you really want is some mechanism to make sure that all the writes are done before you pull the trigger and launch a command buffer, display a frame, trigger a texture upload, whatever.
HP the machine
By 2020, 30 billion connected devices will generate unprecedented amounts of data. The infrastructure required to collect, process, store, and analyze this data requires transformational changes in the foundations of computing. Bottom line: current systems can’t handle where we are headed and we need a new solution.
Hewlett Packard Enterprise has that solution in The Machine. By discarding a computing model that has stood unchallenged for sixty years, we are poised to leave sixty years of compromises and inefficiencies behind. We’re pushing the boundaries of the physics behind IT, using electrons for computation, photons for communication, and ions for storage.
The Machine will fuse memory and storage, flatten complex data hierarchies, bring processing closer to the data, embed security control points throughout the hardware and software stacks, and enable management and assurance of the system at scale.
The Machine will reinvent the fundamental architecture of computers to enable a quantum leap in performance and efficiency, while lowering costs over the long term and improving security.
The industry is at a technology inflection point that Hewlett Packard Enterprise is uniquely positioned to take advantage of going forward. The Machine demonstrates the innovation agenda that will drive our company, and the world, forward.
- fabric-attached memory,
- file-system abstractions for FAM,
- a "Librarian File System" for maintaining shared data,
- remote virtual memory access,
- extensions to configuration and management capabilities,
The code base is called "linux++", but not ready yet.