Weave Net
Weave Net 1.2 delivers performance close to standard networking on today’s common x86 servers thanks to “fast data path”
Weave fast data path just works
The most important thing to know about fast data path is that you don’t have to do anything enable this feature. If you have tried 1.2, you are probably using fast data path already. When we were considering the technical options for improving the performance of Weave Net, many of them implied limitations to the existing feature set, compromising such features as robust operation across the internet, firewall traversal, or IP multicast support. We didn’t want to force users to choose between a “fast” mode and a “features” mode when they set up a Weave network.
In any case where Weave can’t use fast data path between two hosts it will fall back to the slower packet forwarding approach used in prior releases. The selection of which forwarding approach to use is automatic, and made on a connection-by-connection basis. So a Weave network spanning two data centers might use fast data path within the data centers, but not for the more constrained network link between them.
There is one Weave Net feature that, for the moment, won’t work with fast data path: encryption. So if you enable encryption with the --password option to weave launch (or use the WEAVE_PASSWORD environment variable), the performance characteristics will be similar to prior releases. We are investigating the options to resolve this, so if this is important we’d like to hear a bit more about your requirements: please get in touch!
How it works
Weave implements an overlay network between Docker hosts, so each packet is encapsulated in a tunnel header and sent to the destination host, where the header is removed. In previous releases, the Weave router added/removed the tunnel header. The Weave router is a user space process, so the packet has to follow a winding path in and out of the Linux kernel:
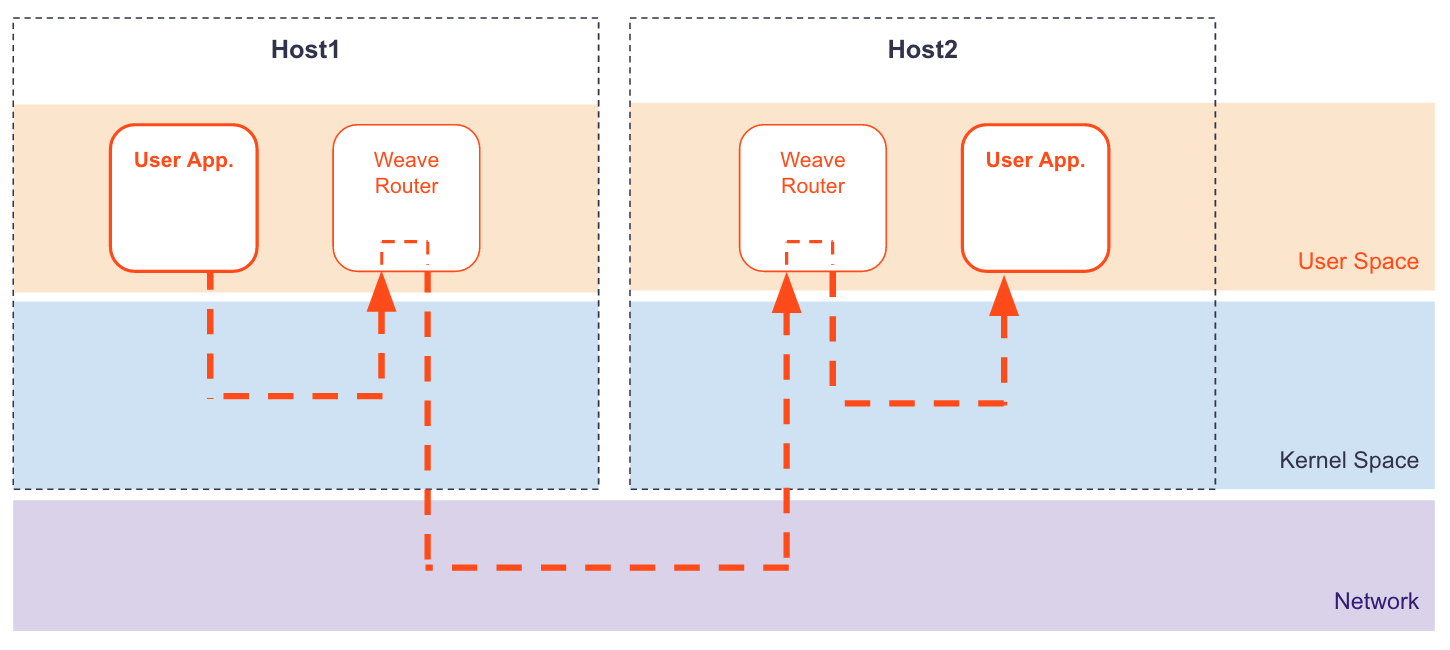
Fast data path uses the Linux kernel’s Open vSwitch datapath module, which allows the Weave router to tell the kernel how to process packets, rather than processing them itself:
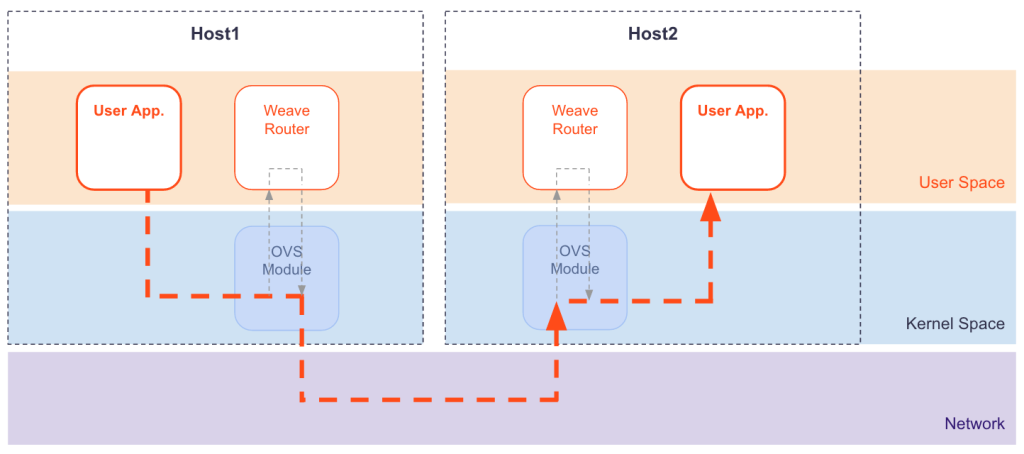
Fast data path reduces CPU overhead and latency because there are fewer copies of packet data and context switches. The packet goes straight from the user’s application to the kernel, which takes care of adding the VXLAN header (the NIC does this if it offers VXLAN acceleration). VXLAN is an IETF standard UDP-based tunneling protocol, so you can use common networking tools like Wireshark to inspect the tunneled packets.